

At KubeCon + CloudNativeCon Europe 2020 Virtual, the CNCF and its members talked about the adoption of cloud-native technologies. As Kubernetes is approaching version 1.19, the technology is starting to mature, and making its way into IT environments big and small, serving as the core for modern, cloud-native applications.
Container platforms need more than just Kubernetes
However, creating a container platform for running production applications needs more than just Kubernetes, including solutions for storage, networking, observability (metrics, logging, tracing), and security, as well as operating systems and compute instances across on-prem and public cloud.
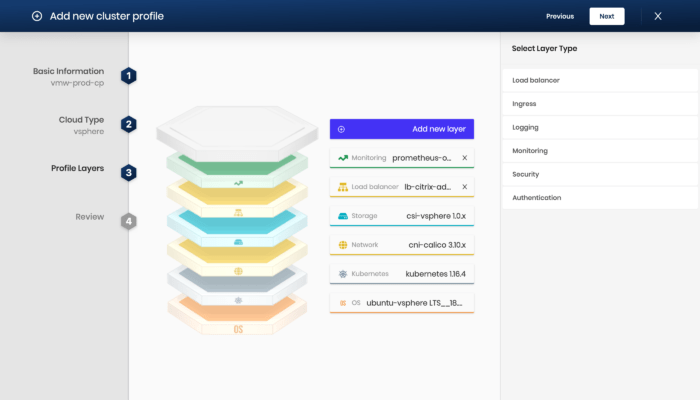
Container Platforms need more than Just Kubernetes
These solutions integrate at the Kubernetes cluster-level, meaning that for every cluster you create, you need to configure all of these tools, resulting in a lot of work at creation-time, especially with different requirements and budgets for different clusters.
Requirements impact cluster design
Because even though it’s just infrastructure, no cluster is created equal. For instance, a development-only cluster for an application using only object storage may not need a commercial storage solution, nor does it need extensive (and more expensive) security software as container security scanning is handled in the CI/CD pipeline.
On the other hand, a production cluster may run a commercially supported Linux distribution instead of a community-supported edition. A cluster running in the public cloud may need a different networking provider as compared to an on-prem cluster running on VMware vSphere.
As you can see, the variation in requirements has a significant impact on each cluster’s configuration profile. And as the technology is maturing and making its way into more and more environments, more and more teams want to use Kubernetes, adding to the different kinds of requirements Kubernetes clusters need to support, like adding GPU drivers for AI/ML workloads or Windows worker nodes for .NET-applications.
But with the complexity of standing up clusters, IT Ops and Cloud Platform teams
gatekeep the creation of clusters, keeping the number of clusters deployed low, sometimes even limiting to a single cluster for all workloads. While this removes the symptoms of this complexity for IT Ops teams, it does prevent app teams from tailoring Kubernetes to their specific needs.

IT Ops and Cloud Platform teams are the gatekeepers for Kubernetes cluster creation
And this is in direct conflict with the core ‘on-demand and self-service’ characteristics of cloud computing; IT Ops is again saying ‘no’ to creating tailored infrastructure because of their own inability to manage and reduce complexity, comparable to the static on-prem virtualized environments many environments still run on.
The solution is not simply a matter of automating the complexity of creating new clusters; as automation only solves for a few pre-defined cluster configuration profiles, and still leans on IT Ops to provision these profiles. Teams definitely need more flexibility than just a single automated deployment configuration.
Tailoring requirements to individual teams
Instead, solving this challenge requires thinking about how to put this automation into the hands of the teams that need these tailored clusters, like data science engineers requiring specific Linux kernel modules or GPU drivers and development teams that need a specific Kubernetes version or Ingress controller, so they can create these profiles in a self-service, on-demand manner, allowing them to tailor clusters to their specific needs.
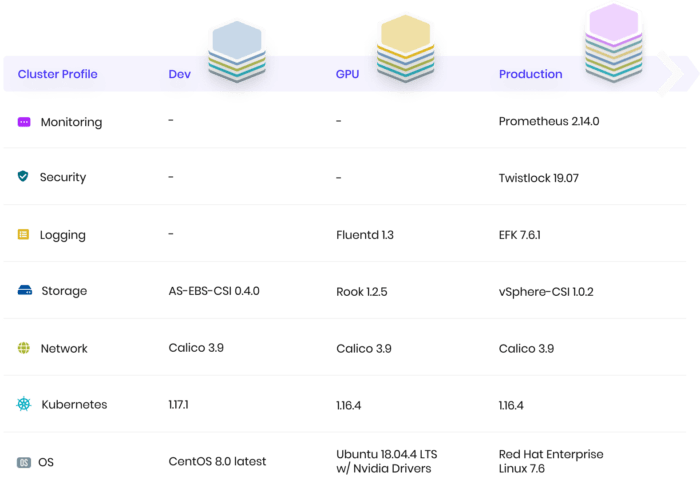
Tailoring cluster configuration to the requirements of individual teams
This does not mean that everything goes, however. IT Ops should still be in control of the configuration options, vetting each option for budgetary, compliance, and operational requirements. However, app teams should have the freedom to create clusters when and how they need them, maximizing the value of Kubernetes for these teams and removing the roadblocks traditionally associated with provisioning infrastructure, like operational overhead, long implementation projects and inertia to change.
Removing infrastructure inertia increases business value
As clusters move from a single cluster for all workloads to single-purpose clusters, the value, and risk, associated with each cluster decreases. Think of it this way: if it’s the only cluster you have and all workloads run on it, the impact of cluster failure or an upgrade-gone-wrong is high. It’s not uncommon to see clusters left untouched due to fear of things breaking when upgrading and building up technical debt as time goes on, increasing chances of things breaking in production.
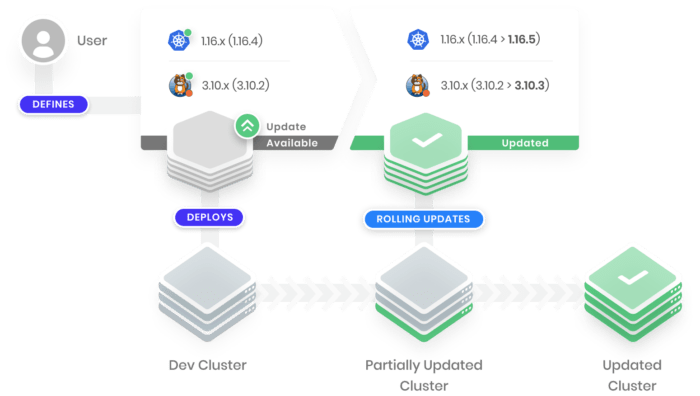
On the other hand, if it’s easy to move your workload to a new cluster and it’s the only workload running on that cluster, why bother upgrading or patching that cluster? This loose coupling of cluster instances to workloads actually removes much of the operational burden. Knowing this, teams can safely move from a perennial ‘single cluster’ approach to single-purpose, tailored and ephemeral clusters without dependencies on other teams or other applications, reducing infrastructure fragility and increasing flexibility. In other words, with the right enabling tools in place, more clusters actually decrease the operational burden and move it from IT Ops to the app teams.
This self-service approach for Kubernetes cluster deployment doesn’t force teams to use a ‘one-size-fits-all’ cluster configuration that doesn’t actually ‘fit’ any team, decreasing team velocity, efficiency, and happiness, as well as business value gotten from using Kubernetes in the first place.
Instead, teams get exactly what they need, without the limitations and trade-offs introduced by infrastructure inflexibility or optimizing for operational considerations to cope with the technical complexities of running many heterogeneous Kubernetes clusters.
So the answer seems easy: optimize cluster configuration for the developer experience and business outcomes instead of optimizing for operational shortcomings to compensate for fear of breaking production. But how do you do that?
Safely put Kubernetes in the hands of your developers
The trick is choosing, and knowing, what your core business is, as an IT Op or Cloud Platform team. And knowing what isn’t. You shouldn’t need to be an expert in Kubernetes and all of the additional tooling to be able to serve app and data science teams. Because building Kubernetes clusters is hard, no matter which way you look at it.
In the end, for most organizations, it’s about the business value the Kubernetes ecosystem helps you realize, not about Kubernetes itself. Learn how Spectro Cloud’s flexible managed-service-like approach offers self-service clusters to your application developers and data science teams based on their specific requirements, while keeping the operational burden of management low.

